

从零玩转ShardingSphere分库分表 (概括)
前言
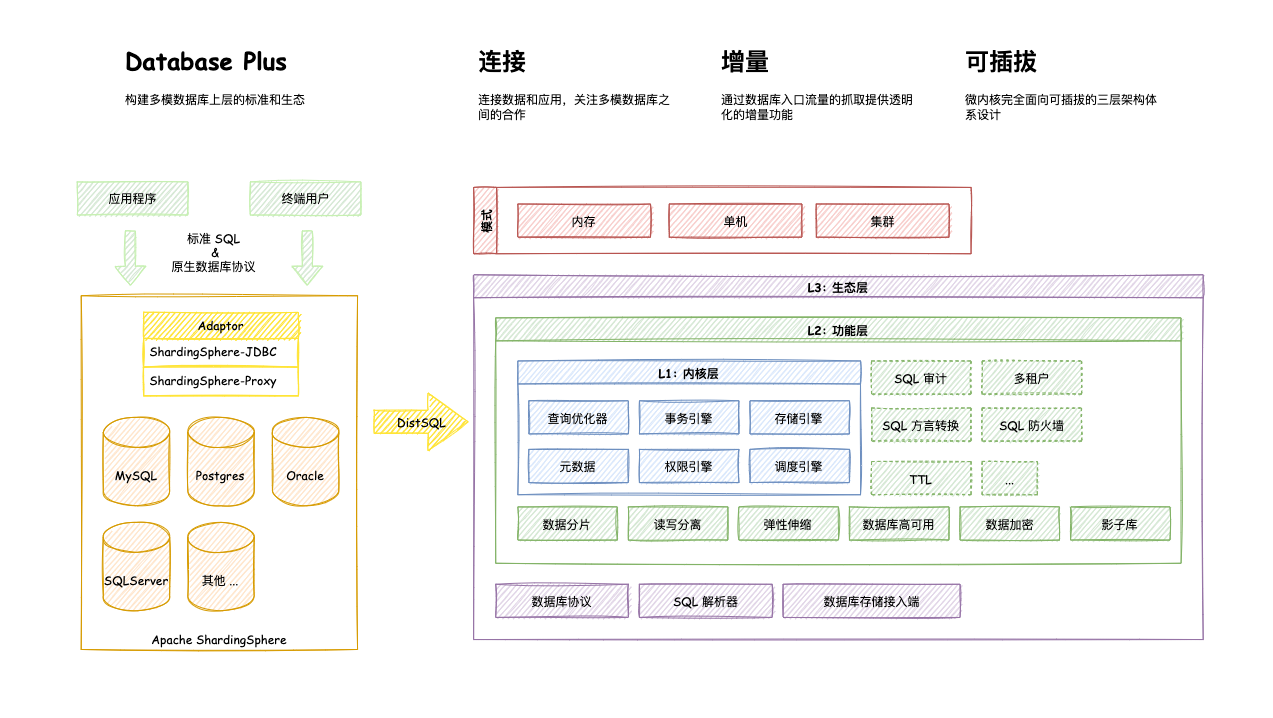
Apache ShardingSphere 产品定位为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。ShardingSphere
站在数据库的上层视角,关注他们之间的协作多于数据库自身。
- 连接:通过对数据库协议、SQL 方言以及数据库存储的灵活适配,快速的连接应用与多模式的异构数据库;
- 增量:获取数据库的访问流量,并提供流量重定向(数据分片、读写分离、影子库)、流量变形(数据加密、数据脱敏)、 流量鉴权(安全、审计、权限)、流量治理(熔断、限流)以及流量分析(服务质量分析、可观察性)等透明化增量功能;
- 可插拔:项目采用微内核 + 三层可插拔模型,使内核、功能组件以及生态对接完全能够灵活的方式进行插拔式扩展,开发者能够像使用积木一样定制属于自己的独特系统。
- 架构图 ↓
分库分表中间件
-
Mycat
- https://mycat.org.cn/
- Mycat是一个要部署在服务器上的软件,类似于上面的Proxy
- 使用Mycat需要有一定的运维能力
-
ShardingSphere(重点)
- http://shardingsphere.apache.org/index_zh.html
- 简介
- Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈
- 由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成
- 提供标准化的数据水平扩展、分布式事务和分布式治理等功能
- ShardingSphere 定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力
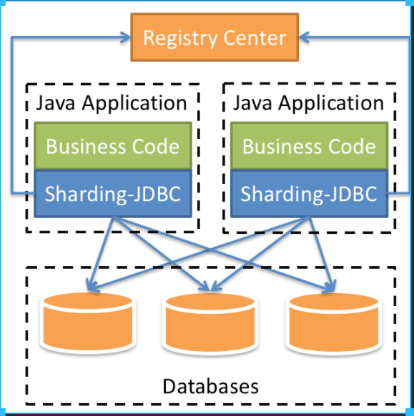
- Sharding-JDBC
- Sharding-JDBC 定位为轻量级 Java 框架
- 以 jar 包形式提供服务,无需额外部署和依赖
- 核心功能 -数据分片
- 读写分离
- 结构图 ↓
- 我们可以看到它的结构- JavaApplication是我们自己的程序引入 Sharding-JDBC 通过它来进行数据库交互-我们只需要定制策、算法即可
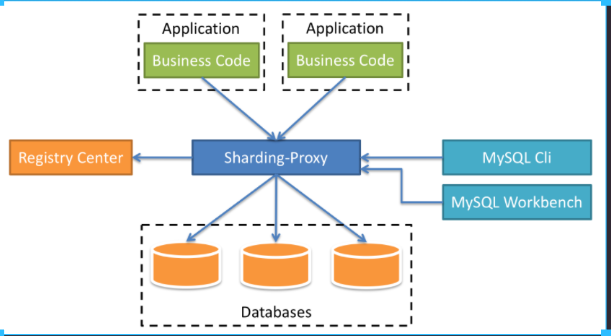
- Sharding-Proxy
- Sharding-Proxy 类似于mycat
- 它定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。
- 目前仅支持 MYSQL PstgreSQL
- 结构图 ↓
- Sharding-Sidecar
- Sharding-Sidecar 目前正在规划中
- 定位为 Kubernetes 的云原生数据库代理,以 Sidecar 的形式代理所有对数据库的访问。
核心概念 (重要)
-
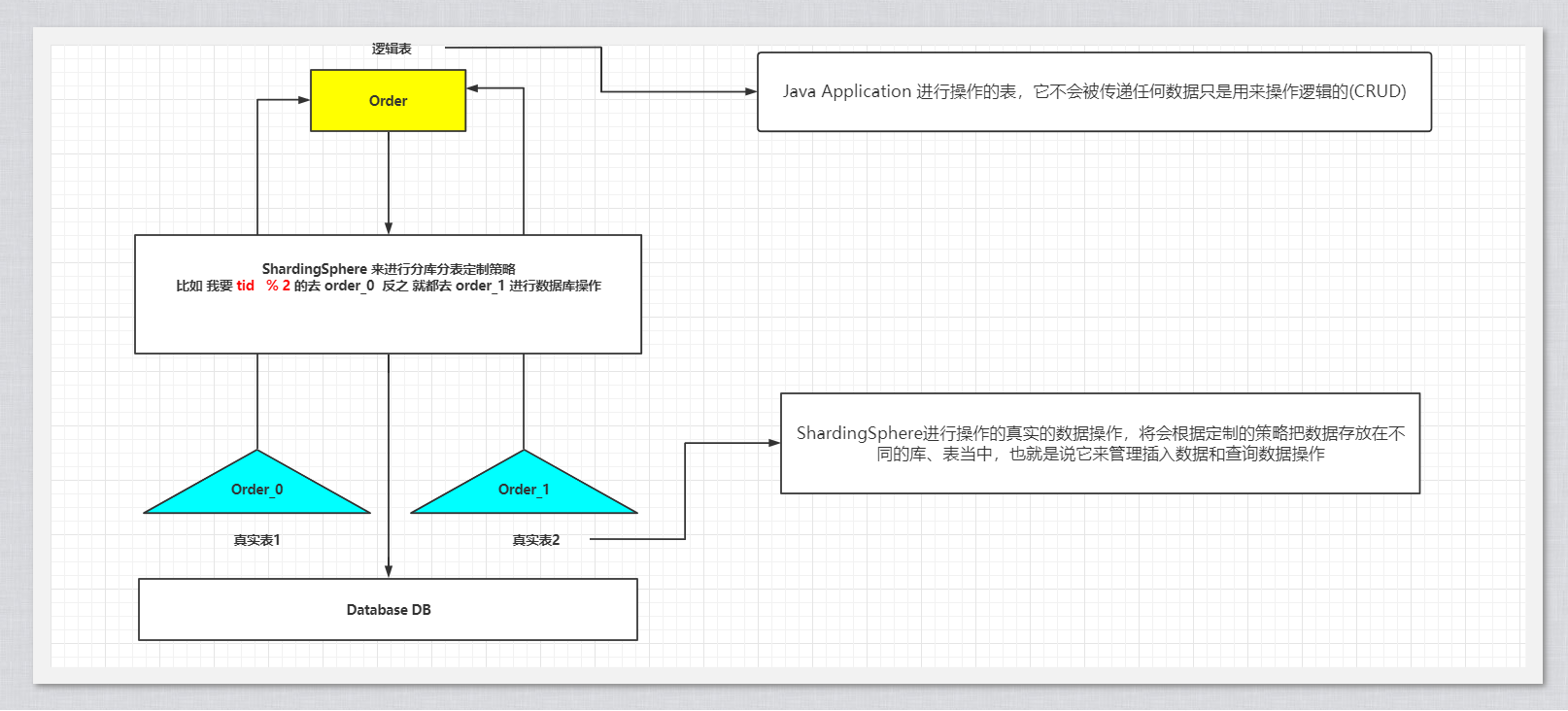
逻辑表
- 水平拆分的数据库(表)的相同逻辑和数据结构表的总称。
- 拆分之后的表,t_order_0,t_order_1 逻辑表名为t_order
-
真实表
- 在分片的数据库中真实存在的物理表
- t_order_0具体的表
-
讲解图
-
数据节点
- 数据分片的最小单元。由数据源名称和数据表组成
- 自定义数据源配置名称是自己定义的哦
spring.shardingsphere.datasource.names=db0- 示例: ds0.t_order (数据源名称.表名)
-
绑定表
- 指分片规则一致的主表和子表
-
广播表
- 指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。
- 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
-
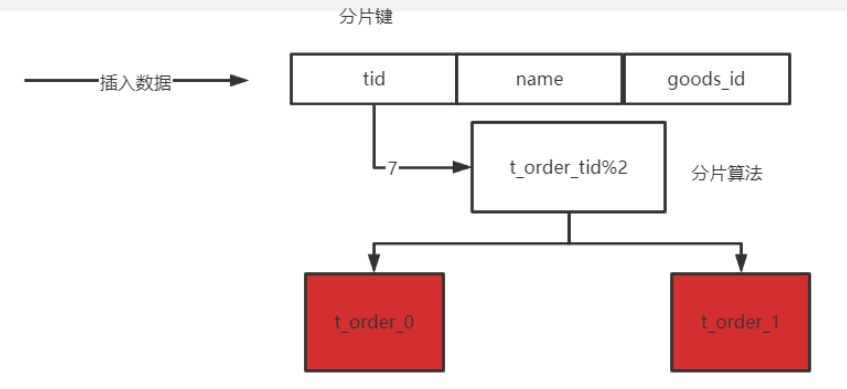
分片键
- 用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。
-
分片算法
- 通过分片算法将数据分片,支持通过 =、>=、<=、>、<、BETWEEN 和 IN 分片
-
分片策略
- 真正可用于分片操作的是分片键 + 分片算法,也就是分片策略
-
分片键与分片算法原理图

评论区